Semantic Interoperability in Health AI
Introduction
So this article will be a very high level tutorial to understand what semantic interoperability is in practice, and why it’s absolutely fundamental to health research and the development of clinical AIs.
Caveats!
Before I begin – for the purposes of this deep dive, we’re not going to touch on the other basics of health data access – things like anonymisation of patient records, opt-outs, ethics and conditions of access etc. – which are regulatory and legal matters. These are absolutely fundamental to health data research as well, but they fall outside the scope of this particular article. Also, in this article I will be using a very simplistic description of Digital Medical Device. Clearly these are quite heavily regulated, so what I'm referring to is simply for broad illustration.
Context
Okay, so let’s start. Imagine you want to build a Digital Medical Device (DMD) to improve health outcomes for a particular group of patients.
A common type of DMD is something which tracks a regular element of an individual patient’s health situation – such as their vital signs, or blood sugar, or medications dosing. All of these require constant tracking of the target values, looking for deviations from appropriate values and then alerting patient, carer and doctor when these occur.
Broadly speaking, this sort of DMD is often implemented with an IoT device that the patient wears or updates to gather the data on an ongoing basis, which in turn feeds an app or online cloud application and an AI which establishes when to alert patients and doctors.
Data requirements
We will now look at a highly simplified Digital Medical Device concept, so we can explore the importance of the data, and the importance of semantic interoperability within the dataset.
Semantic interoperability is essential to building large datasets of the type which are necessary for AI development and training.
To give some context to this deep dive, let’s imagine that you want to find out the best mediation dosing parameters for patients with a particular disease, so that they enjoy the best ‘steady state’ of medications, with as few peaks or troughs as possible. With the steady state, the patient should be able to have a good quality of life and be independent. With patchy medications adherence or an inappropriate medications regime, they will suffer needlessly and need ongoing medical interventions at high expense.
You intend to develop a digital medical device that will send alerts when peaks or troughs happen to ensure the patient gets high quality remote care. You already have a clinical hypothesis from expert knowledge and literature reviews, such as theoretically safe parameters for broadly different types of patients by cohort. However, your Digital Medical Device needs to be calibrated to each individual patient, not just the recommended values.
This is where historical health data is used. To build this sort of Digital Medical Device, you would need to first look at a statistically valid sample of health data from pre-existing patients.
Examples of data to be examined could include:
- Type of medication prescribed.
- Body mass index, age, gender etc. and factors that impact medication dosing.
- How often they presented to a clinical setting with a complication of their condition (especially one directly related to over/underdosing of their medication).
- Complicating factors, such as co-morbidities, mental health or learning difficulties, (poor) socio-economic profile.
- All other relevant data to help calibrate your AI.
Why Semantic Interoperability matters so much
Now we hit the semantic interoperability issue. To get the best quality dataset for your AI, you need:
- As much data on relevant patients as possible.
- As much detail on those patients as possible.
In short, you need high quality medical records.
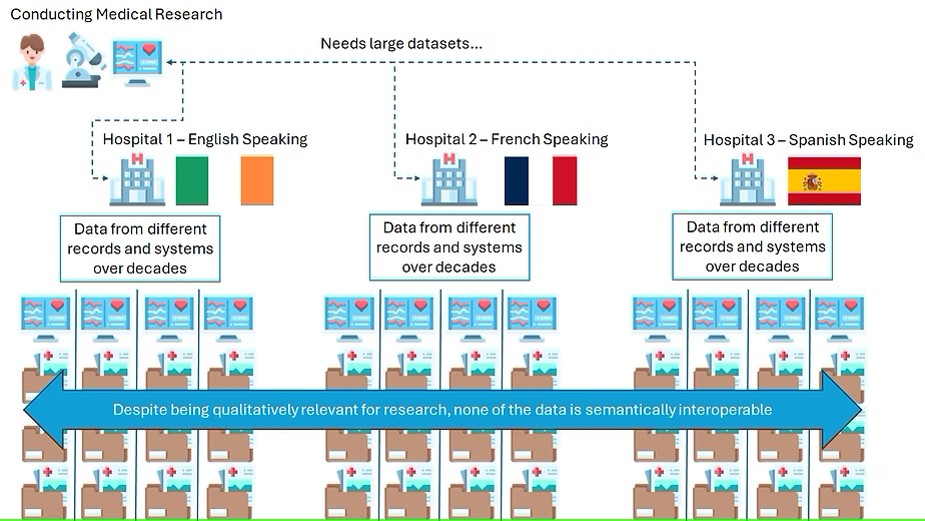
In our example, let's assume that we want to try and construct a large dataset and we are offered good datasets from Ireland, France and Spain. The health records seem qualitatively good, as they hold the necessary information per patient.
However, you now run into the specific semantic interoperability challenges. For your dataset to be large enough to be valid for AI prototyping, you need it to be standardised down to the level of every single clinical term and value of relevance. Unfortunately, your medical records:
- Are compiled with different written languages.
- The medical coding is of varying quality.
- They have been assembled across a 30-year period, with changes in how doctors and nurses referred to specific clinical concepts and values.
- Have a mixture of abbreviations or truncated values which are specific to individual hospitals and hospital applications, such as laboratory values from specific machines used locally.
Achieving Semantic Interoperability
To make the dataset semantically interoperable, you will be required to carry out many, if not all, of the following steps:
- Establish which language will be used – English, French or Spanish – to represent all the data.
- Establish which clinical terminology will be used (SNOMED, ICD, LOINC etc.)
- Translate all the data to one language
- Encode all data into one clinical terminology.
- Investigate the local terms and abbreviations and map to contemporary clinical terms.
- Ensure that all the clinical terms are consistent over the 30-year period, by mapping older concepts and codes to contemporary terms.
- Apply the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) which is also very commonly used to standardise health data from different sources.
As can be imagined, this work can be incredibly laborious. While some Machine Learning tools are available to convert medical data to coded concepts, other elements require a large degree of manual curation and examination. For this reason, curating medical data sets in usable form for researches is an industry all of itself, requiring people with many different skills.
Over time, thanks to a convergence in the use of clinical terms, more automation and more agreement on how to apply data models, these costs should go down, and cleaner, progressively more interoperable health datasets should increase. But this is, of course, a major undertaking.